引言:人工智能商品开发人员要提前一步,让用户体验自己的品牌,和用户取得联系,塑造粘性,进而在激烈的市场竞争中领跑。
2024必定是人工智能领域人声鼎沸的一年。尽管刚进入3月,但是关于人工智能的报道已多次占有今日头条。就在上月,OpenAI发布文本生成视频大实体模型Sora,其生动逼真实际效果立即清空了在这片细分化轨道中努力奋斗的创业者。几天之后,英伟达显卡的市值达到2万亿元,不复存在上更快完成市值从1亿美元到2万亿美元的公司。正所谓“如果你发现金矿石时,最好的生意并不是挖币,反而是卖铲子”,英雄人物变成人工智能时期“乌克兰危机”最大的赢家。
就在大伙儿感慨时“世上只有二种AI,一种是OpenAI,另一种是其他AI”沉默无言了好久的Anthropic发布大小王,由OpenAI前科学研究高级副总裁创建的企业发布了最新的Claude3实体模型,各项性能指标已全面超出GPT4。
AI行业风云变幻,也说明了这一行业还处于初级阶段。技术升级太快,暂时领先的公司可能在一夜之间被新技术应用刷新。尽管出现了一些让人眼花缭乱的技术,但是它们并没公布或布署。例如前面提到的Sora,截止到出文,还没有正式向公众开放。
形成AI的研发及本地部署中间差距很大。现阶段,大家应用的形成人工智能商品一般布署在云端,并在当地浏览(如ChatGPT网页页面),但无法满足所有需求,并会产生一些安全隐患。
最先,伴随着大型模型的日益繁杂,在有限网络带宽下,云和当地间的传送变得紧张。比如,波音飞机787飞机场每秒钟形成5G数据信息。假如上传至云、运算输入参数并返回,飞机场或许已经飞出去多少公里(按800千米/小时计算)。若上飞机应用人工智能作用但在云端布署,则此传输速率不可以符合要求。
此外,一些用户的机密信息和隐私信息一定要使用云服务器吗?很明显,放到当地比云更是让客户安心。
不管生成式人工智能有多强大,怎样部署在当地总是一个在所难免难题。尽管现在面临一些艰难,但是这是行业发展的趋势。
艰难取决于把握好“大模型”装进“小机器设备”。留意,这儿的“尺寸”相对来说。云计算身后可能是一个占地面积数万平方米数据中心,而本地部署需要让形成人工智能从你的手机上运作。手机没液氮冷却,并没有无边无际的电力工程,怎样布署人工智能?
异构计算是一种很有可能解决方案
高通芯片异构计算人工智能模块(下称高通芯片人工智能模块)为市场提供了行得通解决方案。也就是通过CPU、GPU、NPU与高通芯片感应器中心和运行内存子系统的协作,完成了人工智能部署的目地,大大提升了人工智能感受。

图:特殊工业产品设计使不同类型的运算单元更加紧凑 由来:高通芯片
异构计算的原理是让不同种类的Cpu善于不同的工作“专业人员做专业的事”。CPU善于顺序程序,适用必须低延时的使用场景。与此同时,神经网络模型等一些比较小的传统式实体模型(CNN),或是一些特定的大语言模型(LLM),解决CPU非常方便。GPU更倾向于并行计算高精密文件格式,如视频游戏,对图像清晰度要求比较高。
CPU和GPU的诞生率较高,大家已经非常熟悉,而NPU相对性更像是一种新技术应用。NPU是专门针对完成低能耗、加快人工智能逻辑推理量身定做的神经网络处理器。NPU在连续使用AI时,必须以低能耗稳定输出高峰值性能,才能体现最大优点。
比如,当客户玩重负荷游戏的时候,GPU要被彻底占有,或者用户已经访问好几个网页页面,CPU要被彻底占有。这时,NPU做为一个真正的人工智能专用型模块,将承担与人工智能有关计算,以确保用户的人工智能感受稳定。
总的来说,CPU和GPU是为了协调能力设计方案的通用Cpu,便于程序编写。他们负责电脑操作系统、与游戏其他软件。NPU起源于人工智能。人工智能是它自己的工作中。主要是通过放弃一些便于程序编写的特点,完成了更高峰值性能和能耗等级,一路护卫客户的人工智能感受。
当我们把 CPU、GPU、NPU 高通芯片感应器神经中枢与运行内存分系统集成在一起,即异构计算架构设计。

图:高通芯片AI模块包含Hexagon NPU、Adreno GPU、高通芯片Oryon或 Kryo CPU、高通芯片感应器核心和内存分系统 由来:高通芯片
高通芯片人工智能模块搭载了高通芯片 Oryon 或 Kryo CPU、 Adreno GPU 、 Hexagon NPU 及其高通芯片感应器核心和内存分系统。Hexagon NPU作为重要部件,经过多年迭代更新,已经达到全球领先的AI解决水准。以手机app为例子,集成化高通芯片 AI 引擎的第三代高通骁龙 8 适用全球领先的LPDR5x运行内存,频率快达4.8GHz,使其能够以非常快速的芯片运行内存读写速度运作百州等各大语言模型Llama 二等,以此来实现非常快的token形成率,给用户带来全新的体验。
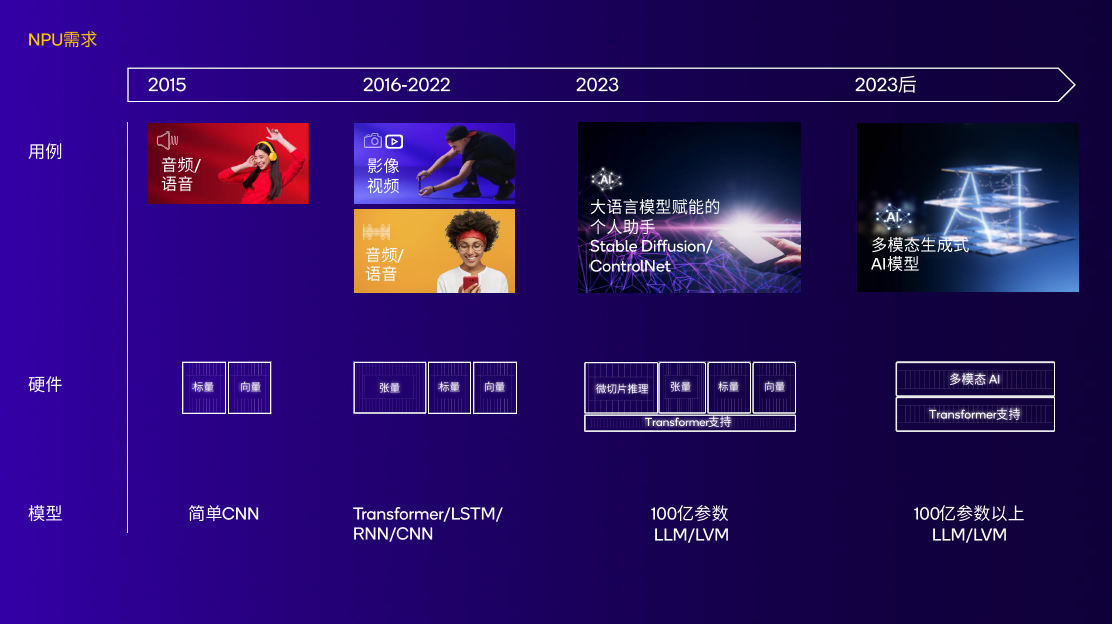
图:伴随着AI测试用例和模型不断演变,NPU完成了性能卓越、低能耗 由来:高通芯片
近年来,高通芯片对NPU的探索并不是这样。假如追朔Hexagon NPU的由来,返回2007年,其实就是生成式AI进到大众视野的15年以前。假如追朔Hexagon NPU的由来应当返回2007年,其实就是形成人工智能进到大众视野的15年以前。高通芯片公布的第一个Hexagon DSP出现在了高通骁龙软件上,DSP控制与标量架构设计变成高通芯片将来几代人NPU的前提。
2015年后,高通骁龙820Cpu搭载了第一个高通芯片AI模块;
2018年,高通芯片在高通骁龙855中向Hexagon NPU增强了偏微分网络加速器;
2019年,高通芯片在高通骁龙865上拓展了终端设备侧人工智能测试用例,包含AI显像、AI视频、AI视频语音等服务;
2020年,Hexagon NPU迎来转型架构升级。标量、空间向量、偏微分加速器的结合,为高通芯片将来的NPU架构设计打下基础;
2022年,第二代高通骁龙8里的Hexagon NPU引入了一系列重要技术革新。标量、空间向量、偏微分加速器的结合,为高通芯片将来的NPU架构设计打下基础;
2022年,第二代高通骁龙8里的Hexagon NPU引入了一系列重要技术革新。微切片技术提升了运行内存高效率,减少了功能损耗,提升了人工智能特性的4.35倍。
第三代高通骁龙8于2023年10月25日正式公布。
做为高通芯片科技公司第一个专门给形成人工智能倾力打造的移动应用平台,其集成化Hexagon NPU是当前高通芯片面对形成人工智能最新发布的、最好设计方案。
因为高通芯片为人工智能开发者和中下游生产商提供了一套完整的解决方案(这一部分将于第三部分详细说明),而非独立给予处理芯片或软件程序流程。
这就意味着高通芯片可以选择硬件开发和改进,找到现阶段人工智能开发设计的瓶颈,并进行有针对性的改善。
比如,为何需要注意内存带宽的技术细节?当我们将角度从芯片提高到AI大型模型开发时,我们不难发现内存带宽是大型语言模型token造成的瓶颈。第三代高通骁龙8的NPU架构设计之所以能协助加速AI大型模型的研发,是因为其专业提升了内存带宽效率。
这类效率的提高主要受益于二种技术的发展。
一是微切成片逻辑推理。将神经元网络分为好几个单独实行的微切成片,规避了10层以上的cpu占用,最大限度地利用了Hexagon 标量、空间向量和偏微分网络加速器在NPU中,并降低能耗。二是当地4位整数金额(INT4)计算。它可以加快INT4层、神经元网络和偏微分的货运量,同时提升内存带宽高效率。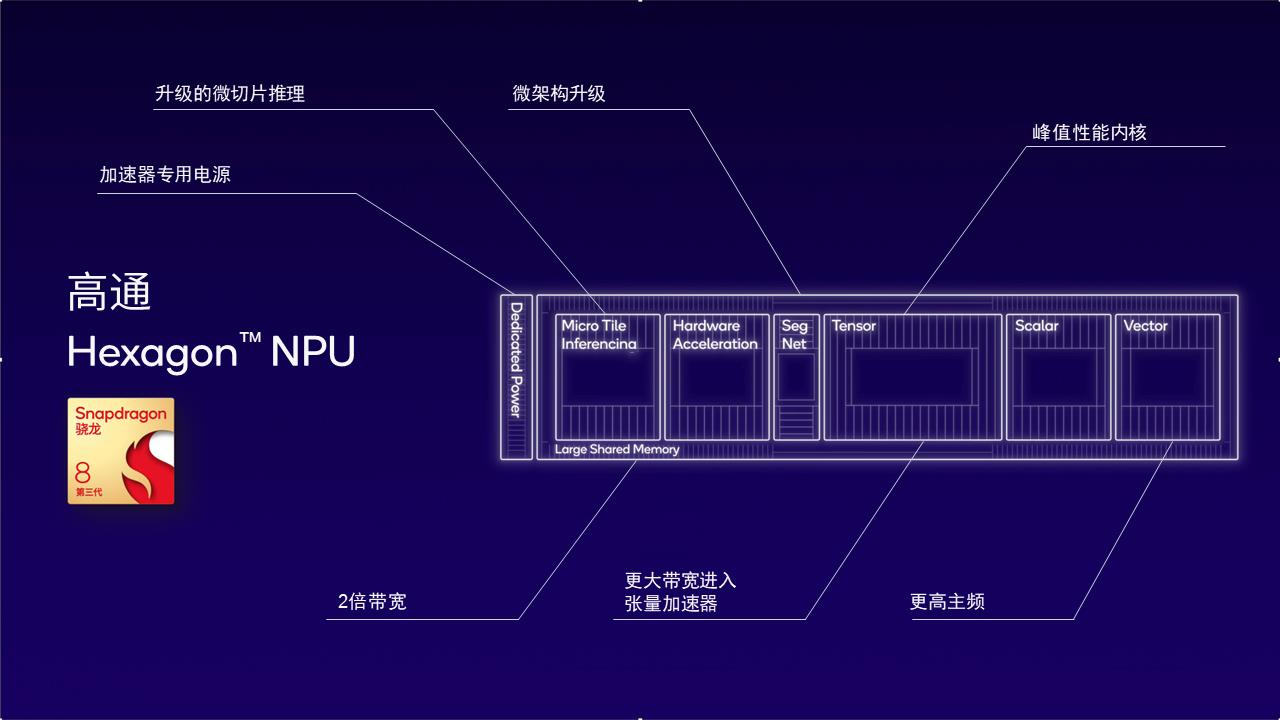
图:Hexagon,第三代高通骁龙8 NPU以低能耗实现更好的AI特性
2月26日,世界移动通信大会(MWC 2024)在巴塞罗那拉开序幕。根据高通骁龙X Elite,高通芯片向世界展示了世界上第一个在终端侧运作超出70亿参数大中型跨模态语言模型(LMM)。该方法可以接收文本和音频输入(如歌曲、交通状况声频等),并依据音频内容形成多轮对话。
因而,Hexagon集成化 在NPU的智能终端上会有怎样的AI感受?它是怎么做到的?美国高通公司详尽拆卸了一个案例。
依靠移动智能终端的AI旅游小助手,用户可以直接规定实体模型整体规划旅行行程。AI小助手可以马上得出航班行程提议,根据语音对话调节输入参数,最终通过Skyscaner软件建立完备的飞机航班日程。
如何做到这类一步到位的感受?
第一步是由自动语音识别客户的语言(ASR)将实体模型Whisper转化成文字。该方法有2.4亿主要参数,主要是在高通芯片感应器核心运作;
第二步是应用Llama 或是百州大语言模型根据文本信息生成文本回应,该模型在Hexagon中 在NPU上运行;
第三步,开源系统TTS以在CPU上运行(Text to Speech)实体模型将文字转换为视频语音;
最后一步是由解调器技术实现数据连接,应用Skyscaner软件进行购票实际操作。
在这个市场井喷式前夜,开发人员必须把握机遇
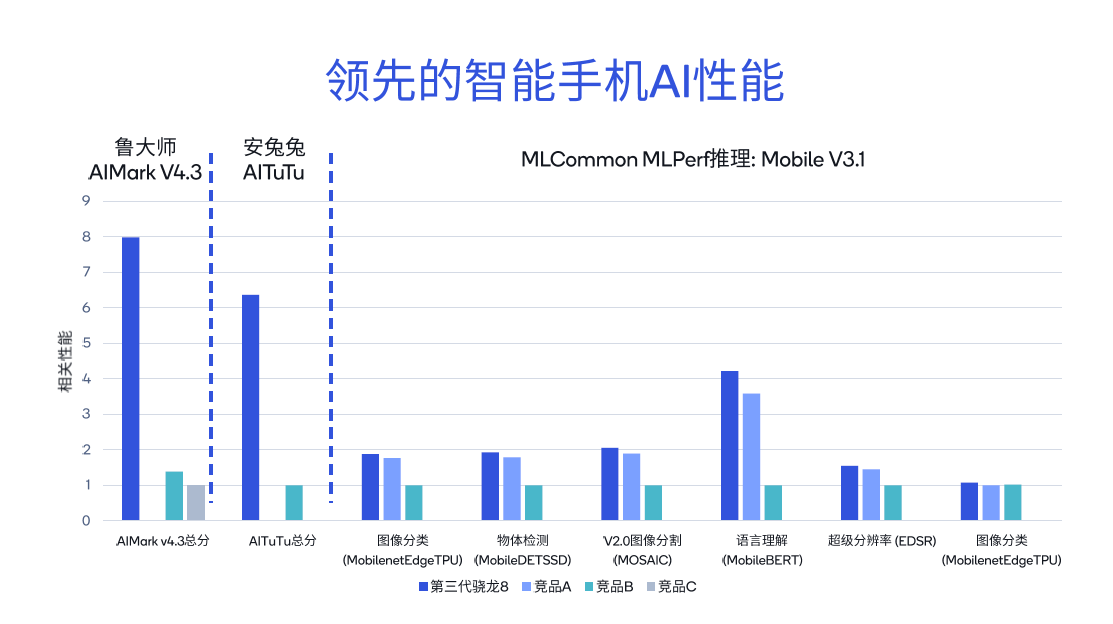
采用不同的专用工具检测高通骁龙和高通平台的AI使用性能,不难发现其评分是类似市场竞争商品的几倍。
 在这个市场井喷式前夜,开发人员必须把握机遇
在这个市场井喷式前夜,开发人员必须把握机遇
采用不同的专用工具检测高通骁龙和高通平台的AI使用性能,不难发现其评分是类似市场竞争商品的几倍。从电脑鲁大师AIMark V4.依据统计检验结论,第三代高通骁龙8的总成绩比竞争对手B高5.7倍,比竞争对手C高7.9倍。
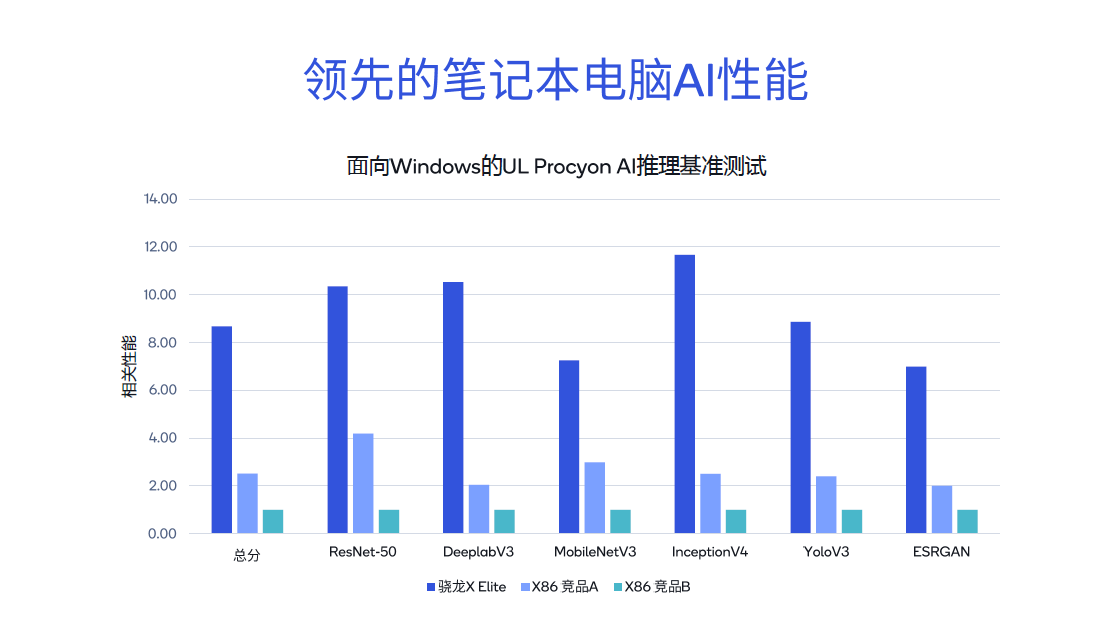 在安兔兔评测AITuTu统计检验中,第三代高通骁龙8的总成绩是争夺商品B的6.3倍。MLComon MLPerf逻辑推理的差异子项目,包含分类任务、语言逻辑和超级屏幕分辨率,也进行了详细较为。
在安兔兔评测AITuTu统计检验中,第三代高通骁龙8的总成绩是争夺商品B的6.3倍。MLComon MLPerf逻辑推理的差异子项目,包含分类任务、语言逻辑和超级屏幕分辨率,也进行了详细较为。
进一步较为高通骁龙X 在Resnet-50中,Elite与其它X86架构设计市场竞争、在Deeplabv3等检测中,高通骁龙X Elite显现出很明显的领先水平,其统计检验分别为X86架构设计竞争对手A的3.4倍和竞争对手B的8.6倍。因而,不论是在PC端运作Microsoft, Copilot,或是文本文档引言、文本文档创作等形成人工智能运用,感受如丝般顺滑。
行业领先的人工智能特性并不都是高通芯片人工智能引擎的贡献。准确的说,高通芯片对人工智能制造商的受权是全方位的。
 关键在于高通芯片AI模块。
关键在于高通芯片AI模块。
主要包括Hexagon NPU、Adreno GPU、高通芯片Oryon CPU(PC服务平台)、高通芯片感应器神经中枢和内存分系统。该异构计算架构设计为终端侧产品提供了低能耗、更高效的软件开发平台,具备专门工业产品设计以及不同零部件的优良融洽。
根据优秀硬件,高通芯片上线了人工智能软件栈(高通芯片人工智能 Stack)。该产品的诞生是为了了解决人工智能开发里的顽疾——针对不同的平台,应数次开发同样的作用,无效劳动。AI Stack适用全部流行人工智能架构,OEM制造商和开发的人可以在互联网上建立、优化布署人工智能应用软件,以实现“一次开发,全网平台布署”,大大降低了R&D工作人员的无效劳动。

图:高通芯片AI软件栈协助开发者“一次开发,全网平台布署” 由来:高通芯片
除此之外,也有高通芯片刚在MWC2024上发表的AI Hub。
AI Hub是一个包括近80个人工智能模型3d模型库,包含形成人工智能实体模型、传统式人工智能实体模型、图像识别技术或人脸识别实体模型、百州、Stable Diffusion、Whisper等实体模型。开发工作人员能从人工智能逐渐 在Hub中挑选需要使用模型形成二进制软件,完成人工智能 开发的“1394连接”。
总体来说,假如竖向看深层,高通芯片在硬件(AI模块)、手机软件(AI Stack)和素材网(AI Hub)全面加快生产商人工智能开发进度三个维度。从纵向来看,高通的商品已经覆盖了绝大多数的终端设备侧机器设备(第三代高通骁龙8支持手机等终端,X Elite创变AI PC商品)。
人工智能运用正处在井喷式前斟酌期。
在教育领域,人工智能能够为学生学习的能力以及发展制定个性化的教学工作计划;在医疗领域, 人工智能可用于寻求新的抗菌素种类;在养老服务领域,不久的将来一些人口老龄化难题严重的地区,人工智能终端设备可用于搜集老年人全部个人信息,可以帮助防止应急医疗事故纠纷。
之所以是“井喷式前”,恰好是由于没有大规模布署。另一方面,AI运用做为比较容易让用户产生黏性的产品之一,具有极强的市场优势。
人工智能商品开发者要提前一步,让用户体验自己的品牌,和用户取得联系,塑造黏性,进而在激烈的市场竞争中领跑。
(文章转载自Deeptech深科技)